What is Uniq Command
Linux'taki uniq komutu , bir dosyadaki tekrarlanan satırları raporlayan veya filtreleyen bir komut satırı yardımcı programıdır. Basit bir ifade ile uniq, bitişikteki tekrarlayan satırları tespit etmeye yardımcı olan ve aynı zamanda yinelenen satırları silen bir araçtır. Uniq, giriş dosyasındaki (argüman olarak gerekli olan) bitişik eşleşen satırları filtreler ve filtrelenen verileri çıkış dosyasına yazar.
Syntax
uniq [OPTION]... [INPUT [OUTPUT]]Bunun sözdizimini anlamak oldukça kolaydır. Burada INPUT , tekrarlanan satırların filtrelenmesi gereken giriş dosyasını ifade eder ve INPUT belirtilmemişse uniq standart girişten okur. OUTPUT, uniq komutu tarafından oluşturulan filtrelenmiş çıktıyı saklayabileceğiniz çıktı dosyasını ifade eder ve INPUT durumunda olduğu gibi, OUTPUT belirtilmemişse uniq standart çıktıya yazar.
Example
Şimdi bir örnek yardımıyla bunun kullanımını anlayalım. Burada dikkat edilmesi gereken en önemli nokta, tekrarlayan satırlar bulunacağı için sadece alt alta olanları bulacaktır. Eğer dosya içinde farklı satırlar varsa veya birden fazla dosyayı birleştiriyorsanız sort komutu ile birleştirmeniz gerekmektedir. Şimdi örnekler ile bunu anlamaya çalışalım.
Aşağıdaki görselde dosya içinde aynı satırlar vardır. Ancak alt alta tekrarlanmadığı için cat ve uniq komutunda aynı sonuçları verdiği rahatlık gözlenmektedir.
cat a.txt
uniq a.txt 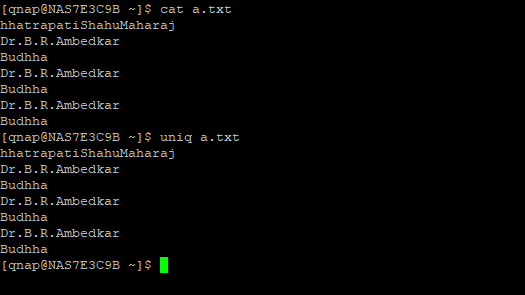
Şimdi sort komutu ile bu işlemi gerçekleştirdiğimiz zaman tektarlayan satırların çıkarıldığını rahatlıkla görebiliriz.
sort a.txt|uniq 
Eğer, tekrarlanan satırların kaç adet olduğunu öğrenmek isterseniz -c parametresini kullanmanız yeterlidir. Aşağıdaki örnek bize ilk satırın üç kez, ikinci satırın bir kez ve üçüncü satırın üç kez tekrarlandığını anlatıyor:
sort a.txt|uniq -c 
Yalnızca tekrarlanan satırları görmek için -d parameresini kullanmamız yeterlidir. Yinelenmeyen satırları atar. Aşağıdaki örnekte ChhatrapatiShahuMaharaj satırı atlanmıştır. Ancak binlerce satır olduğunda çok işinize yarayacaktır.
sort a.txt|uniq -d 
Eğer daha garantici olmak istiyorsanız, çapraz kontrol etmek için, -cd parametrelerini beraber kullanabilirsiniz.

- -i seçeğini kullanarak karakterlerin büyük/küçük harf duyarlılığını göz ardı edebiliriz.
- Bazen yinelenen satırları filtrelemek için bazı alanları atlamamız gerekebilir. Bunu -f seçeneği ile gerçekleştirebiliriz. Örneğin ilk satırı atlamak için -f 1 şeklinde kullanabiliriz.
Şimdi biraz daha karmaşık bir probleme bakalım. Örneğin, 10 bin dosyanız var. Her dosya 100 bin satırdan oluşuyor. Amacımız, iki veya daha fazla dosyadaki tüm yinelenen satırları ve ayrıca yinelenen girişler içeren dosyaların adlarını bulmak istiyoruz.
Bazı Linux sistemlerde, aşağıdakileri yapmak yeterli olabilir. Sonucu bir dosyaya yazılmasını sağlamak için yönlendirmemiz yeterlidir. “dupes.txt”
sort *.txt | uniq -d >dupes.txt 
Bu satırların hangi dosyalardan geldiğini bulmak için grep komutu ile aşağıdaki seçenekleri kullanabilirsiniz. (Oluşan dupes.txt dosyasını farklı bir konuma alırsanız daha temiz bir sonuç alırsınız.)
grep -Fx -f dupes.txt *.txt 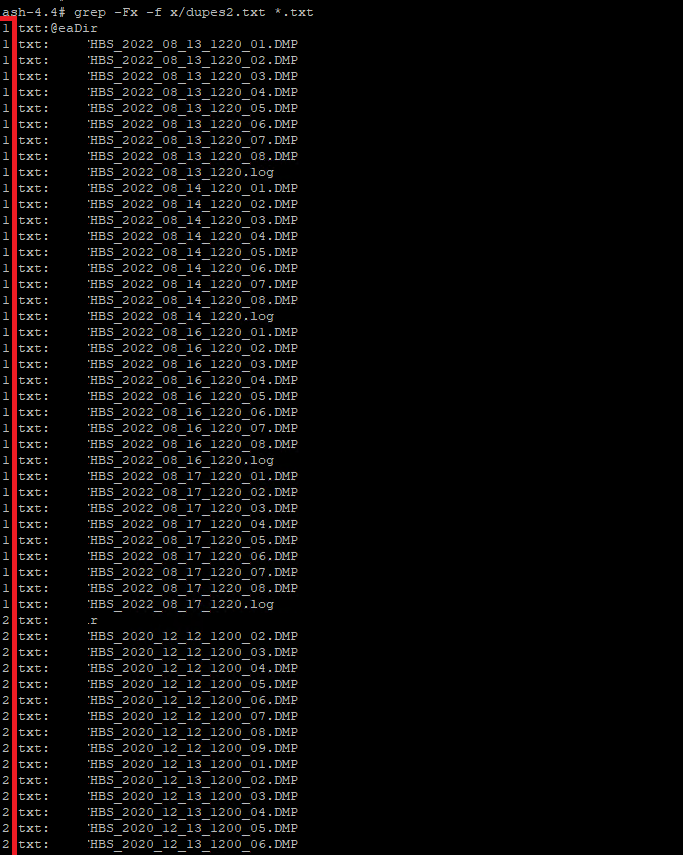
Yukarıda görüldüğü gibi sol tarafta dosya isimleri yazmaktadır. (1,2)